Kubernetes cronjobs are useful to schedule a task to run at a specific time just like the crontab in Linux
Just like any scheduling, Kubernetes cronjobs comes with a set of advanced features which can be configured to an optimal level.
Before you are using Kubernetes cronjobs in production, please check out these Kubernetes cronjobs configuration elements and see if they meet your expectations to avoid any incidents later

Concurrency and Parallelism of CronJob - A Boon or Bane
One of the advancements and adverse settings of Kubernetes cronjobs is its Concurrency and Parallelism
It's a great feature when you handle it right and your job is designed to support concurrency and not every cronjob is designed for concurrency.
For example, Let's say you have a cronjob that is supposed to insert an entry into the database or send a notification to a set of people every N hours.
Now if you have enabled concurrency and parallelism for this cronjob, It would create duplicate notifications and duplicate data on the table which would eventually cause a production incident
Not just this, there are more problems that may arise at a later point if we do not pay attention to detail
Here I have listed some
- Completed and Failed jobs take a lot of memory and CPU and space on the node
- Jobs running for too long and causing conflict between the upcoming run
- Jobs not getting scheduled or scheduled after a long time after the expected time
- Pods/Jobs keep getting restarted due to Out Of Memory or Image Pull Back Off
So there are N number of permutations on what can go wrong
But don't worry, there are settings or configuration specifications which we can use to control all these effects, and prevent them prior
The Ideal Kubernetes CronJob Configuration - Example
Refer to the following image of Kubernetes cronjob YAML created with the recommended guard rail configurations
we will see what each element represent and control shortly. we have also given comments on the image itself for a better understanding
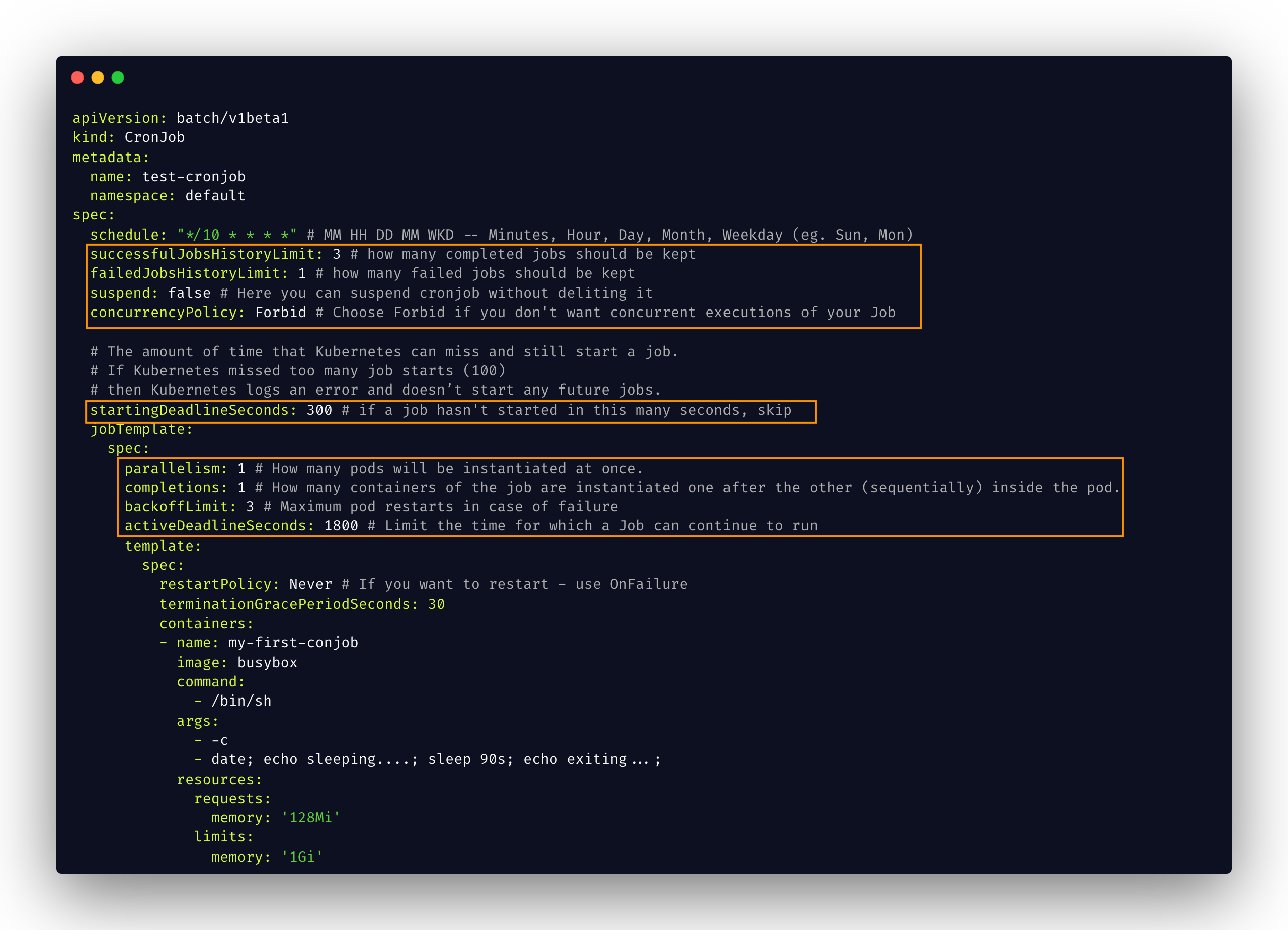
⚡ successfulJobsHistoryLimit :
Control how many completed jobs should be kept, Keeping too many completed jobs and pods would incur additional cost
⚡ failedJobsHistoryLimit
How many failed jobs should be kept, In production you can have this count a little more for later debugging
⚡ concurrencyPolicy
Set to Forbid, if you don't want concurrent executions of your Job. In most cases, you would not want Concurrency on the cronjob. Having this enabled might lead to duplicate execution of your job and eventually duplicate workflows or entries on the DB
For example, if your cronjob is to create entries on DB periodically. If concurrency is enabled you might end up locking the table or creating multiple entries both are bad in production
⚡ startingDeadlineSeconds
How long scheduler can try to create the jobs and pods before they give up
⚡ parallelism
This is closely associated with concurrency, It controls How many pods will be instantiated at once. In most cases, we can just go with one pod
⚡ completions
This controls, How many containers of the job are instantiated one after the other (sequentially) inside the pod.
⚡ backoffLimit
Maximum pod restarts in case of failure. In cases of Image Pull Back Off or Out Of Memory etc
⚡ activeDeadlineSeconds
A Maximum timeout setting or the Limit of time for which a Job can continue to run
Here is the source code you can copy
apiVersion: batch/v1
kind: CronJob
metadata:
name: test-cronjob
namespace: default
spec:
schedule: "*/10 * * * *" # MM HH DD MM WKD – Minutes, Hour, Day, Month, Weekday (eg. Sun, Mon)
successfulJobsHistoryLimit: 3 # how many completed jobs should be kept
failedJobsHistoryLimit: 1 # how many failed jobs should be kept
suspend: false # Here you can suspend cronjob without deliting it
concurrencyPolicy: Forbid # Choose Forbid if you don't want concurrent executions of your Job
# The amount of time that Kubernetes can miss and still start a job.
# If Kubernetes missed too many job starts (100)
# then Kubernetes logs an error and doesn’t start any future jobs.
startingDeadlineSeconds: 300 # if a job hasn't started in this many seconds, skip
jobTemplate:
spec:
parallelism: 1 # How many pods will be instantiated at once.
completions: 1 # How many containers of the job are instantiated one after the other (sequentially) inside the pod.
backoffLimit: 3 # Maximum pod restarts in case of failure
activeDeadlineSeconds: 1800 # Limit the time for which a Job can continue to run
template:
spec:
restartPolicy: Never # If you want to restart - use OnFailure
terminationGracePeriodSeconds: 30
containers:
- name: my-first-conjob
image: busybox
command:
- /bin/sh
args:
- -c
- date; echo sleeping....; sleep 90s; echo exiting...;
resources:
requests:
memory: '128Mi'
limits:
memory: '1Gi'
Hope this helps. If you have any questions of feedback please do let me know in comments section
Cheers
Sarav AK

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content