
In this article, we are going to see how to recover deleted files from an S3 bucket. But this works only for buckets which having Versioning enabled
When you do not have versioning enabled on an S3 bucket and you delete an object, it would be a permanent irreversible change, so you cannot recover those files
It is one of the production recommendations to have versioning enabled and we presume you have versioning enabled on the S3 bucket in which you are trying to recover objects.
To understand how this is possible only in the versioned bucket. Let's quickly learn how versioning works
How Versioning Works on S3
If you enable versioning for a bucket, Amazon S3 automatically generates a unique version ID for the object that is being stored.
For example, in one bucket you can have two objects with the same key (object name) but different version IDs, such as photo.gif (version 111111) and photo.gif (version 121212).
Each object has a version ID, whether or not S3 Versioning is enabled. If S3 Versioning is not enabled, Amazon S3 sets the value of the version ID to null. If you enable S3 Versioning, Amazon S3 assigns a version ID value for the object. This value distinguishes that object from other versions of the same key.
When you enable S3 Versioning on an existing bucket, objects that are already stored in the bucket are unchanged.
Their version IDs (null), contents and permissions remain the same. After you enable S3 Versioning, each object that is added to the bucket gets a version ID, which distinguishes it from other versions of the same key.
Delete Marker or Soft Delete
When you delete an object in a versioned bucket without specifying the version of the object. S3 simply adds a flag called Delete Marker on the object as a new version
This Delete Marker would have its own Version ID and it would be added on top of the versions of the object
Objects with Delete Markers are considered soft deleted and they can be recovered if we remove the delete marker version on the top
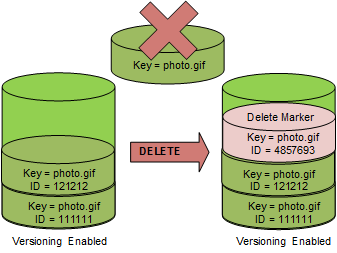
In the preceding image, you can see the delete marker has been added on top of the current versions and when you try to GET the S3 object photo.gif it would try to get the latest version of the object which is the delete marker
If there is a delete marker on the object, S3 would return a NOT FOUND response and say the object is not present
Now to recover all we have to do is remove the Delete Marker version
How to permanently delete - in versioned S3 bucket
You can permanently delete an S3 object by specifying the version that you want to delete. Only the owner of an Amazon S3 bucket can permanently delete a version.
If your DELETE operation specifies the versionId, that object version is permanently deleted, and Amazon S3 doesn't insert a delete marker.
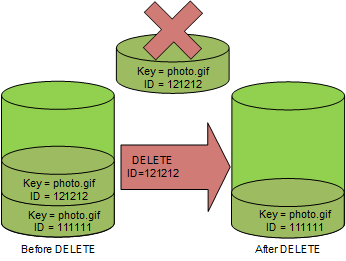
As shown in the preceding diagram, When you specify the VERSION ID on the delete call the object with the corresponding version is permanently deleted
Now we presume that you have understood only objects in versioned S3 buckets with delete markers can be recovered.
Lets move on to the next stage on how to recover all the deleted files in S3 bucket ( with delete marker) recursively with a prefix
RecoverS3 - Open Source tool for efficient recovery
We have created this recover-s3 tool to help you efficiently recover the deleted files from the S3 bucket
but why do you need this tool? can you not do it manually?
Of course, you can, by directly going to the console and removing the delete marker version of the object you want to recover. you can recover the S3 object
But. when you want to do it recursively in a large bucket with Millions of objects. this tool would come in handy
we have added threading to speed up the process. As part of benchmarking, we have been able to recover 10000 files in 8 minutes.
The speed of the script depends on the number of files that you are trying to recover, the network speed and the file size.
As we already mentioned, This script will recover files from S3 that have been deleted by removing the deletemarker from the S3 object.
We have released Version2 of RecoverS3 with the following features
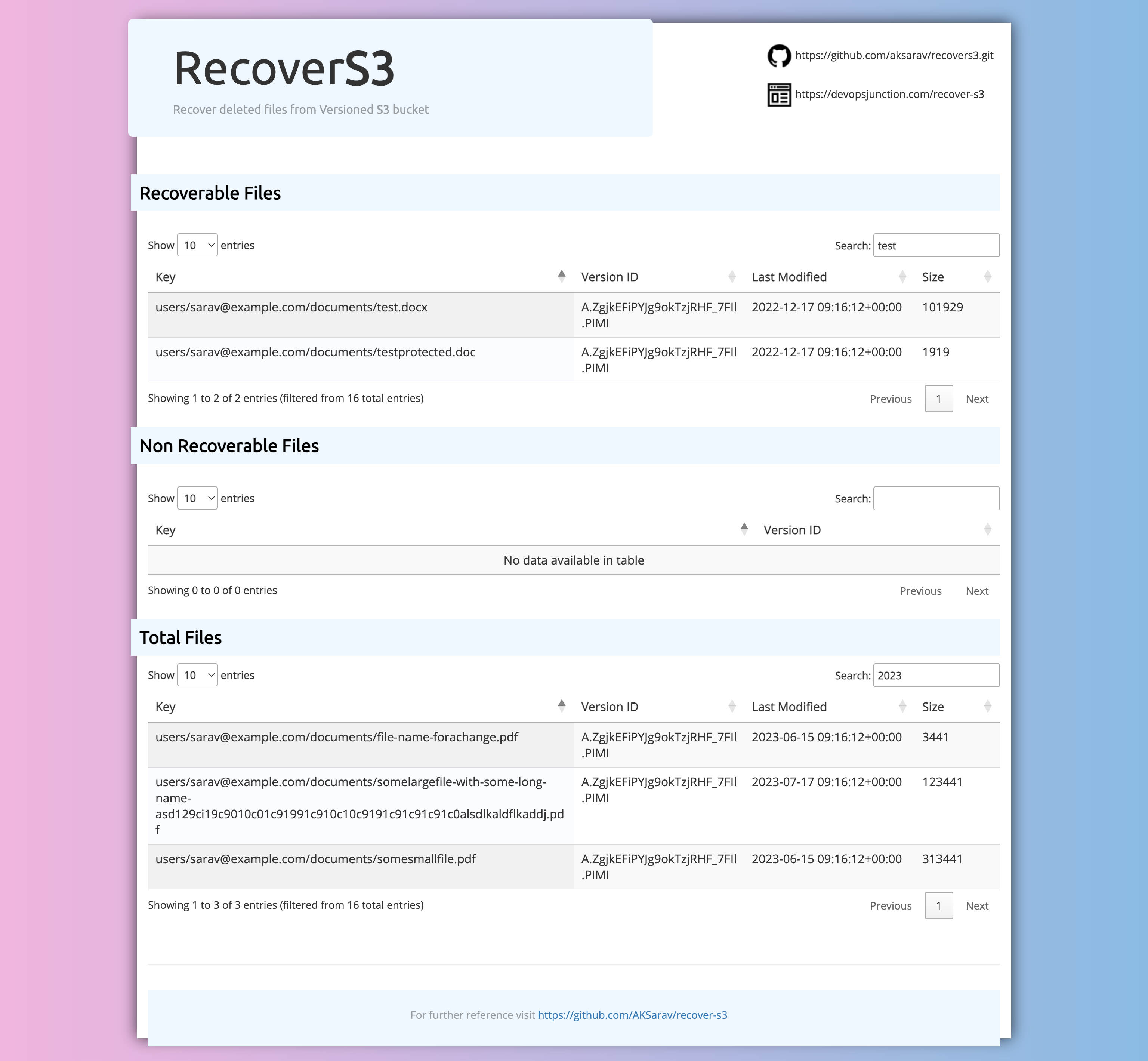
1. Intutive HTML report with Sortable Searchable Data
2. Dryrun feature to validate before actual recovery
3. Validation of Recoverable and Non Recoverable files
Here is a glimpse of the report that Recover S3 version 2 creates. Now you can search, sort and this report is generated with a dry run.
Now let's move on to the installation and pre-requisites for the recover-S3 tool
Pre-requisites
- Python 3
- Boto3
- pip
- AWS Access Key and Secret Key
- Permission to access S3 bucket and list and delete objects
Installation
Clone the repository and install the dependencies.
$ git clone https://github.com/AKSarav/recover-s3.git $ pip install -r requirements.txt
Usage
python recover-s3-files.py [-h] – bucket BUCKET – prefix PREFIX – region optional arguments: -h, – help show this help message and exit – bucket BUCKET S3 bucket name – prefix PREFIX S3 prefix – region REGION S3 region
Example
Here is some example command of recover-s3 that you can use to recover files from a bucket named my-bucket
python recover-s3-files.py – bucket my-bucket – prefix my-prefix – region us-east-1
You can use --dry-run option to validate the recovery and to create the HTML report before going for the actual recovery
python recover-s3-files.py – bucket my-bucket – prefix my-prefix – region us-east-1 – dry-run
Further reading
I would highly recommend you visit our Github repository page and read the latest changes and documentation
https://github.com/AKSarav/recover-s3.git
If you like the product, please do leave a star on GitHub and encourage me. thanks
I hope this helps
If you have any feedback or queries please let me know comments. Pull requests and issues are welcome to the Git repository
Cheers
Sarav AK

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content




