Kubernetes headless service is a Kubernetes service that does not assign an IP address to itself. Instead, it returns the IP addresses of the pods associated with it directly to the DNS system, allowing clients to connect to individual pods directly.
This means that each pod has its own IP address, making it possible to perform direct communication between the client and the pod.
The main difference between Kubernetes service and Kubernetes headless service is that a regular Kubernetes service allocates a single IP address to the service, which is used as a proxy to balance traffic between multiple pods,
whereas a Kubernetes headless service does not allocate an IP address to the service and returns the IP addresses of the individual pods directly to the DNS system.
Hope the following illustration explains the difference between Service vs Headless service
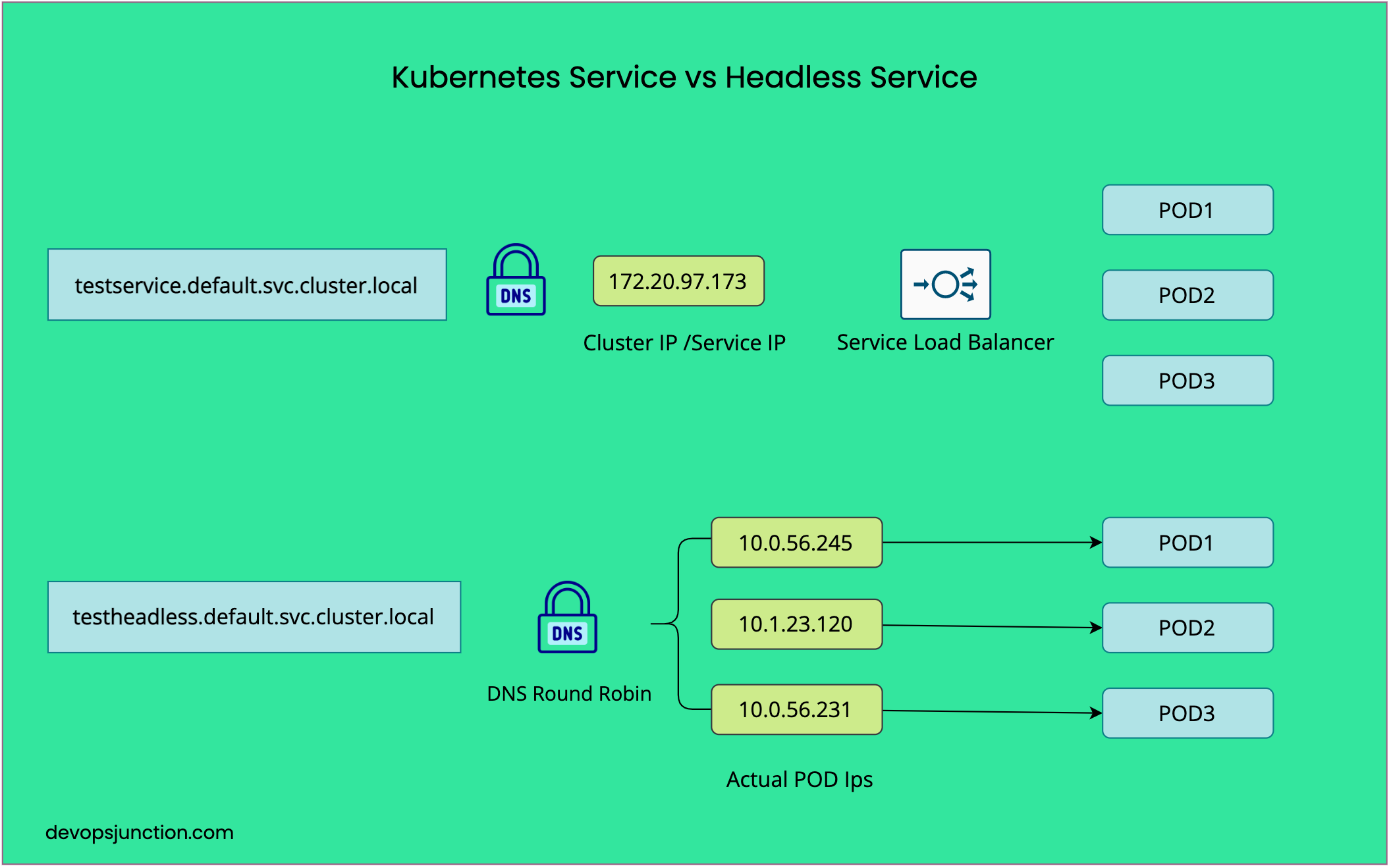
What is Headless Service
Headless service is a ClusterIP type of service with no internal static IP assigned where the actual POD IPs are exposed via DNS round-robin
To understand what is Cluster IP you must be aware of the types of services in Kubernetes
If you are not aware of Kubernetes services and their types Here is a quick glance
These are the types of Kubernetes Service
- ClusterIP (default): Internal clients send requests to a stable internal IP address.
- NodePort: Clients send requests to the IP address of a node on one or more
nodePortvalues that are specified by the Service. - LoadBalancer: Clients send requests to the IP address of a network load balancer.
- ExternalName: Internal clients use the DNS name of a Service as an alias for an external DNS name.
While there are four official types of Kubernetes service ( by definition) there is one more type of service which is the Headless Service
Technically Headless service is of type ClusterIP as you create it
But what makes it headless is setting the spec.clusterIP to None
If you refer to the following image, you can see the same service definition on the left, is converted to headless service ( on the right ) by adding the line ClusterIP: None
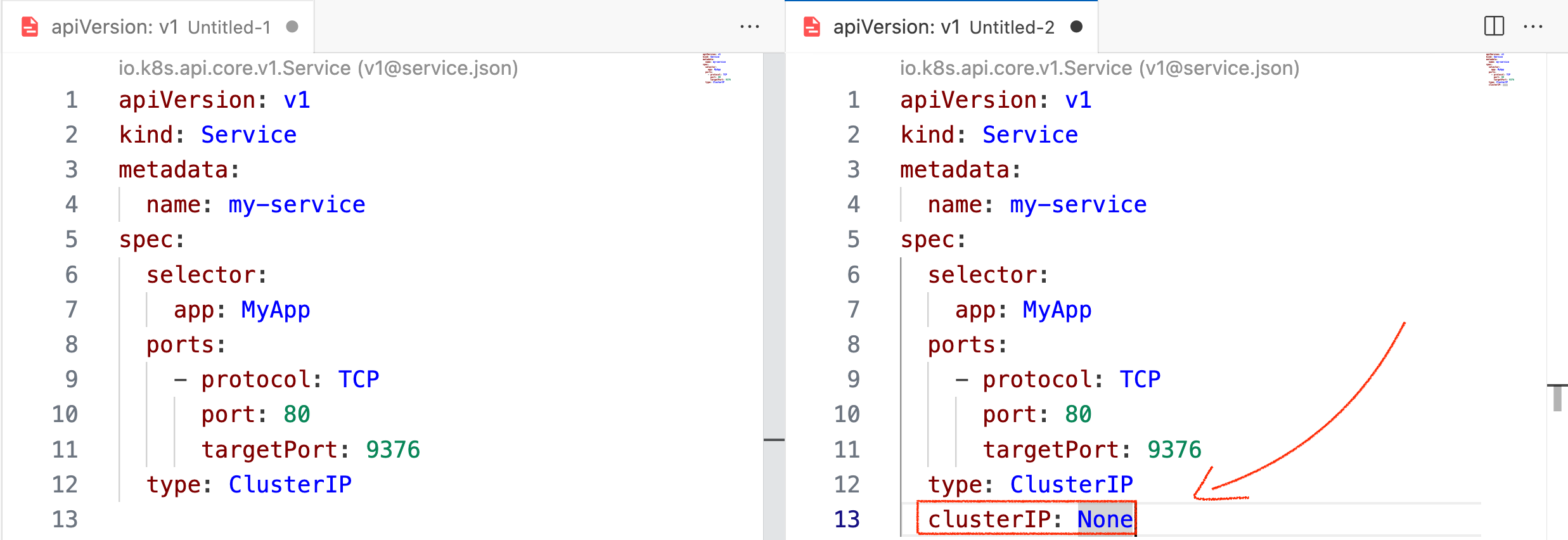
That's all the difference it takes to convert your service to headless service. You just have to let go of ClusterIP assigned and use the POD IPs instead
Here are the actual source codes if you would like to copy
Normal ClusterIP Service example
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: ClusterIP
Headless Service example
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: ClusterIP
clusterIP: None
As we have already mentioned. with ClusterIP set to None. a Service is now a headless service and it exposes the actual POD IPs when you try to nslookup or dig
NodePort/Load Balancer service as a Headless service
You may raise this question. can I convert any of my NodePort / Load Balancer services as a headless service too?
The answer is NO, you cannot. the ClusterIP: None attribute works only with the type ClusterIP, not with any other service type.
On a funny note, For us to say renounce ClusterIP we have to have one first right 😀
When to use Kubernetes Service vs Headless Service
Use a Kubernetes service when you want to provide a stable IP address for clients to access a set of pods, and you want to balance the traffic between the pods based on a load-balancing policy.
This is useful for web applications, microservices, and other distributed systems that require high availability and scalability.
Choose Kubernetes headless service when you want to perform tasks such as port forwarding, DNS lookups, or direct access to individual pods.
This is useful for applications that require direct communication between the client and the pods, or when you want to perform network-related tasks such as accessing a specific pod or performing a DNS lookup.
Headless services are also useful when you want to use external load balancing solutions, such as a hardware load balancer, instead of the built-in Kubernetes load balancer.
Headless Service and Kubernetes Stateful set
Hope you have heard of or used Statefulset in Kubernetes to summarize in a few words
You know Kubernetes replica sets and pods are ephemeral in nature and they share the same blueprint like storage, network etc. to put it in a single word they are basically stateless
What if you want to have a dedicated network, name and order of start/stop and storage for your replicated PODs? that's where statefulset comes
and why it's relevant to Headless service.
Statefulset gives more importance to the pods and also expects the pods to participate in a network communication directly identifying themselves.
If you use the Normal ClusterIP service or any Kubernetes service ( except headless ) the service would have its Common Cluster/Internal IP not the POD's actual IP
so if you want to expose your POD's actual IP and represent it on its own. You need Headless service
So mostly all statefulset type of implementations prefer headless services here are some examples
Here is an example of headless service with Cassandra - refer to this article to see more
apiVersion: v1
kind: Service
metadata:
labels:
app: cassandra
name: cassandra
spec:
clusterIP: None
ports:
- port: 9042
selector:
app: cassandra
Here is another article that talks about setting up mongoDB on Kubernetes and you can see the type of service used
apiVersion: v1
kind: Service
metadata:
name: mongodb-test
labels:
app: database
spec:
clusterIP: None
selector:
app: database
Conclusion
Hope you have learnt about Services and Headless service in this article and also the use cases and the need of Headless service
Also the connection and dependency of headless service with stateful sets of Kubernetes
If you have any questions do let me know in the comments section
Hope it helps. Stay connected and follow me on my linked in and subscribe to our newsletter
Cheers
Sarav AK

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content