Apache Drill is a revolutionary product that identifies itself as a Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage - While it was often represented or perceived as a tool for Data Engineers or Analysts. It is not just for Data Engineers
In this article, we are going to explore an interesting use case of Apache Drill with RDS MySQL
Before we move further you need to understand a few base rock items - required for our objective.
- What is Parquet
- What is Columnar Table Schema
- What is Apache Drill and what it can do?
I will try to summarize all these crisply before we move further

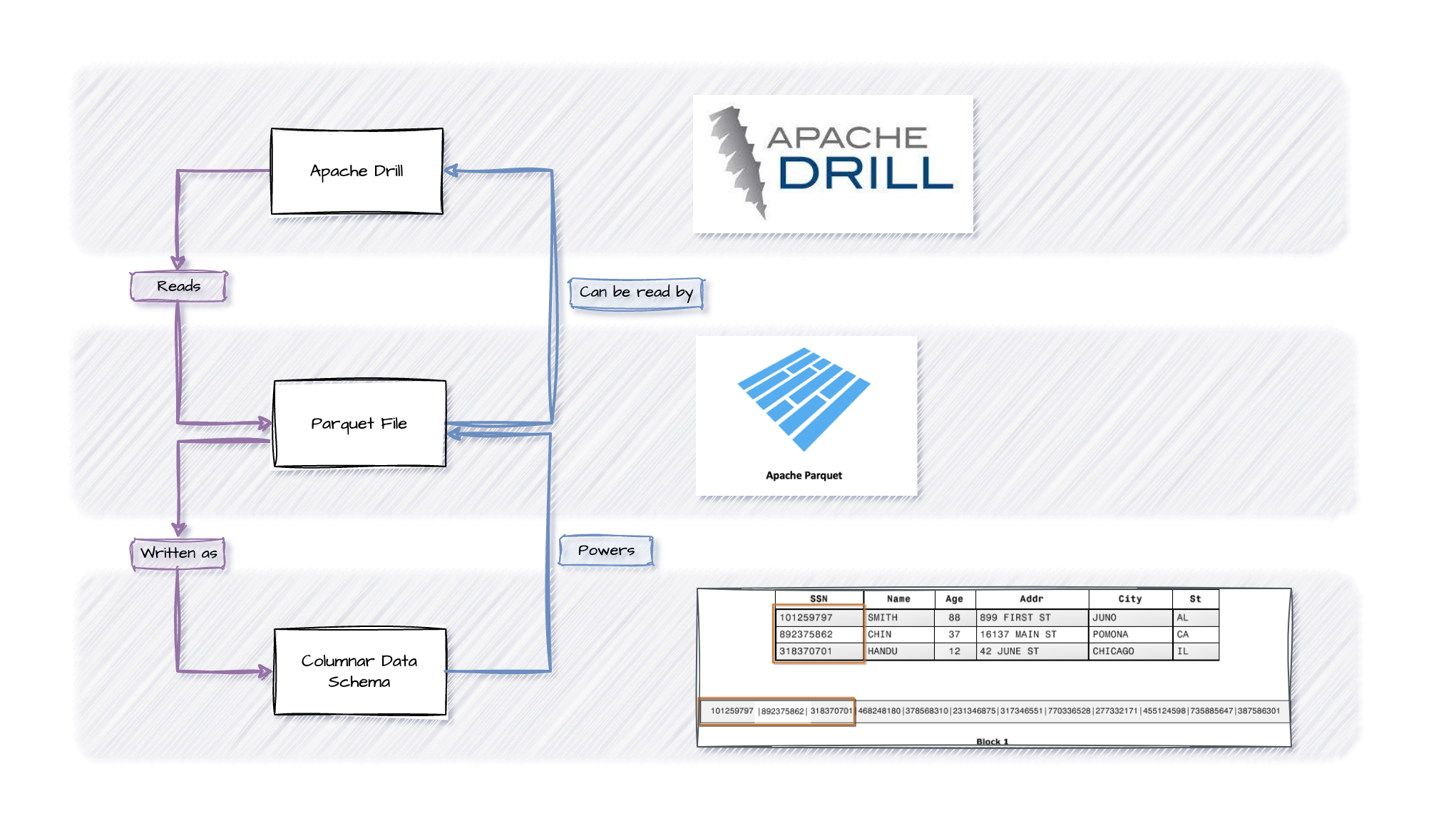
Columnar Data Schema
A columnar data schema refers to the way data is organized and stored in a columnar format. In a columnar schema, each column of a table is stored separately, as opposed to the row-wise storage in traditional row-oriented databases. This organization has several advantages, particularly for analytical processing:
- Compression Efficiency: Similar data values in a column can be encoded more efficiently, leading to better compression ratios. GigaBytes of Data can be stored in a Couple of MBs
- Query Performance: Analytical queries often involve accessing a subset of columns rather than all columns. Columnar storage allows for more efficient retrieval of relevant data.
- Parallel Processing: Columnar storage facilitates parallel processing of queries, as different columns can be processed independently.
Parquet File
Parquet is a columnar storage file format optimized for use with big data processing frameworks. It is designed to be highly efficient for both storage and processing, making it suitable for analytics and data processing workloads. Parquet is particularly popular in the Apache Hadoop ecosystem, but it can be used with various data processing frameworks. The columnar storage format means that data is organized by columns rather than rows, which can lead to better compression and faster query performance, especially for analytical queries that only need to access specific columns.
Key features of Parquet file format:
- Columnar Storage: Data is stored column-wise, allowing for better compression and improved query performance.
- Schema Evolution: Parquet supports schema evolution, allowing you to add, remove, or modify columns without requiring a full rewrite of the data.
- Compression: Parquet supports different compression algorithms, enabling efficient use of storage space.
Apache Drill
Apache Drill is an open-source, schema-free SQL query engine for big data exploration. It supports a variety of data sources, including traditional relational databases, NoSQL databases, and file systems. Drill provides a SQL interface for querying diverse data sources, making it easy for users to explore and analyze data without needing to know the details of the underlying data storage.
Key features of Apache Drill:
- Schema-Free: Drill allows querying data with varying structures, making it well-suited for handling semi-structured and nested data.
- Distributed Query Processing: Apache Drill can scale horizontally, distributing query processing across a cluster of machines.
- Support for Various Data Sources: Drill supports querying data from various sources, including Hadoop Distributed File System (HDFS), relational databases, NoSQL databases, and more.
In summary,
Parquet is a columnar file format designed for efficient storage and processing of big data. -
The FormatApache Drill is a query engine that can interact with diverse data sources, including those using a columnar storage format. -
The Tool to handle the formatThe columnar data schema is an organizational approach where data is stored and processed column-wise, offering advantages in compression, query performance, and parallel processing. -
The Technology behind the Format
Here is the visual representation of how these three things are co-related and we will see shortly why it's needed for our objective
RDS S3 Backup and Parquet
In the previous introduction section, we discussed the benefits of Columnar DB Storage Schema and one of them is Great compression efficiency and size reduction
Due to the compression efficiency of this schema, you can store petabytes of data as a chunks of few Megabytes
You can store AWS RDS backups in S3 in the form of parquet files - this provides greater cost efficiency in your infrastructure.
What would you choose, storing 1TB of backup in EBS volume or storing it as 100MB or below of parquet files?
To give some numbers from my personal experience, 20GB of RDS table can be stored as 20MB or below of parquet files (cumulative) when you do S3 backup
While these 20MB of parquet files are often split or partitioned into smaller chunks based on the no of records, 100K (1Lakh) in a single chunk like that
If you are not aware of this RDS to S3 backup. Read my article here where I talk about automating the RDS to S3 backup
You can read more about RDS S3 export and finer details here on this AWS documentation
Once you have set the RDS s3 export the generated parquet files - you can see your tables are exported as a few hundred parquet file chunks
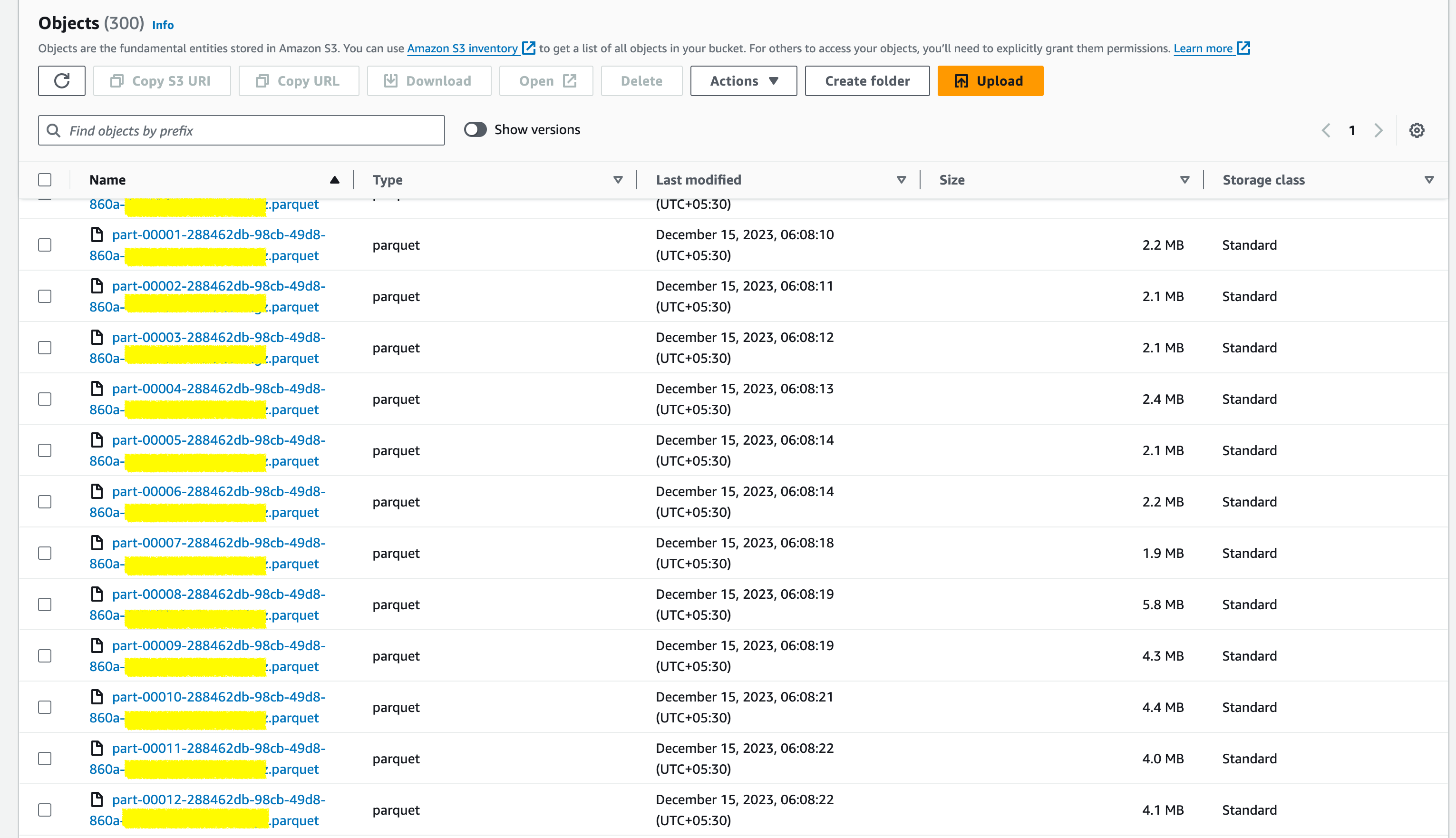
and these parquet files contain the records of our table but in Columnar schema - In a perspective, this is an easy way to convert our large MySQL Row schema to columnar schema
Provided that we now have the tool (drill) and the data (in parquet) we can try to use the drill to analyze this data.
But to connect the tool with the data? well, there are a few options to read the parquet file into Apache Drill. Lets explore
Apache Drill - SQL with RDS backup parquet files
Now we have come to the core objective of reading/analyzing the AWS RDS backup parquet files from S3 with Apache Drill
While Apache drill has a lot of extensions to support multiple data sources
As you can see in the Documentation of Apache Drill, the latest version as of Dec2023 supports a great set of extensions and data sources starting with local file system it is expanding to Hadoop, S3, MySQL, PostgreSQL, Hive, Mongo and the list goes on
While each data source extension has to be enabled manually from the Apache Drill CLI or Console - the default filesystem extension comes pre-enabled
Here is a glimpse of the Drill console where you can easily configure and enable a lot of data source extensions
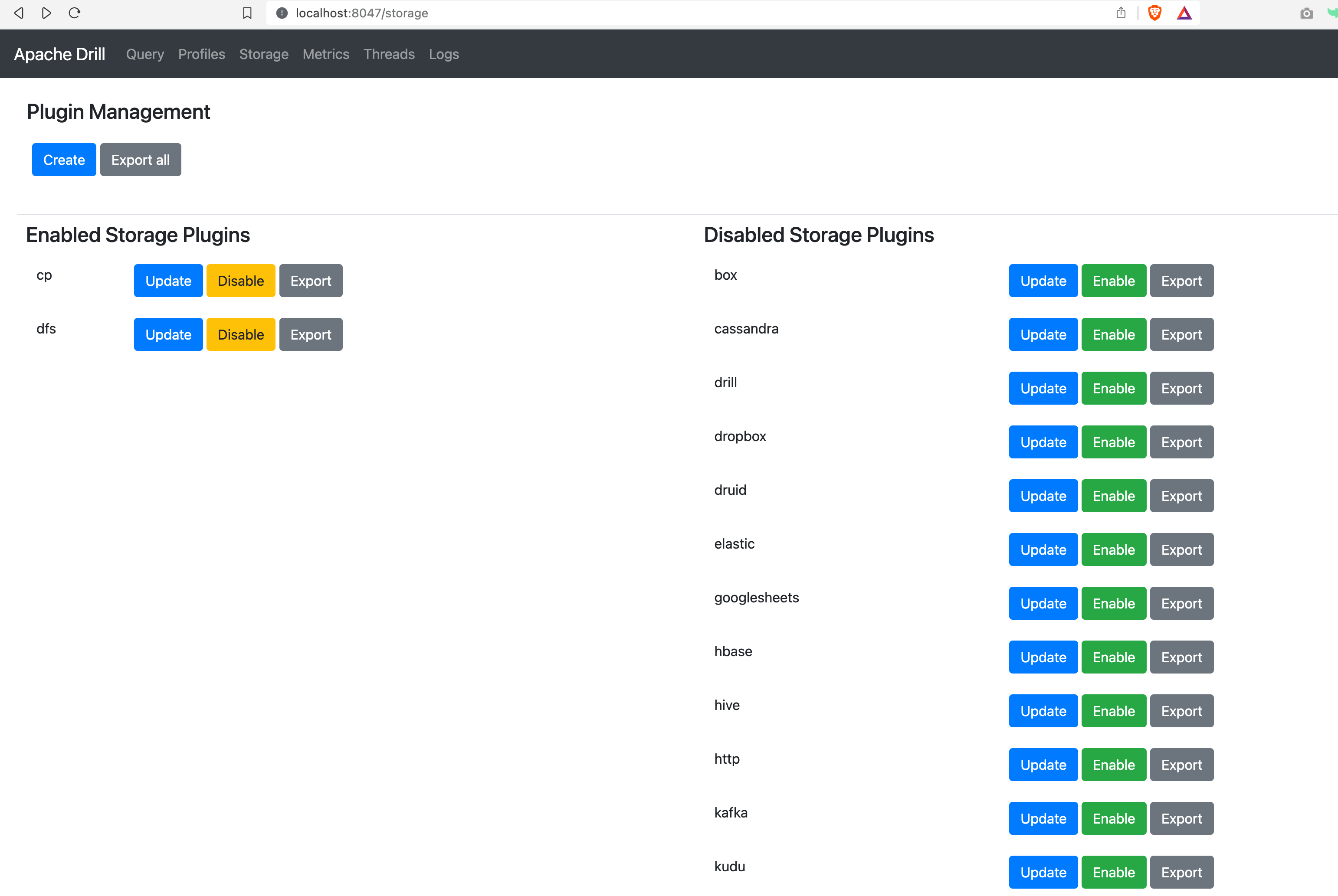
the JSON(cp) and FileSystem(dfs) plugins are enabled by default in most of the distributions
Now we have two options,
- one is to read the parquet file from S3 directly which needs the configuration and enablement of an S3 storage plugin
- second is to download the parquet file to the local filesystem and read using the DFS plugin
Let me walk you through the steps for S3 direct access - But remember downloading the parquet files locally is more efficient than dealing with S3 directly as it has some network latency and delay. Besides
Configure S3 data source or Plugin in Drill
To Enable the S3 datasource do the following steps
- Navigate to the drill Web interface and storage tab [http://localhost:8047/storage]. find the S3 Beneath the disabled storage plugin section. Click on the Enable button
- Once the plugin has been enabled, you can see the S3 start to appear on the
Enabled Storage Plugins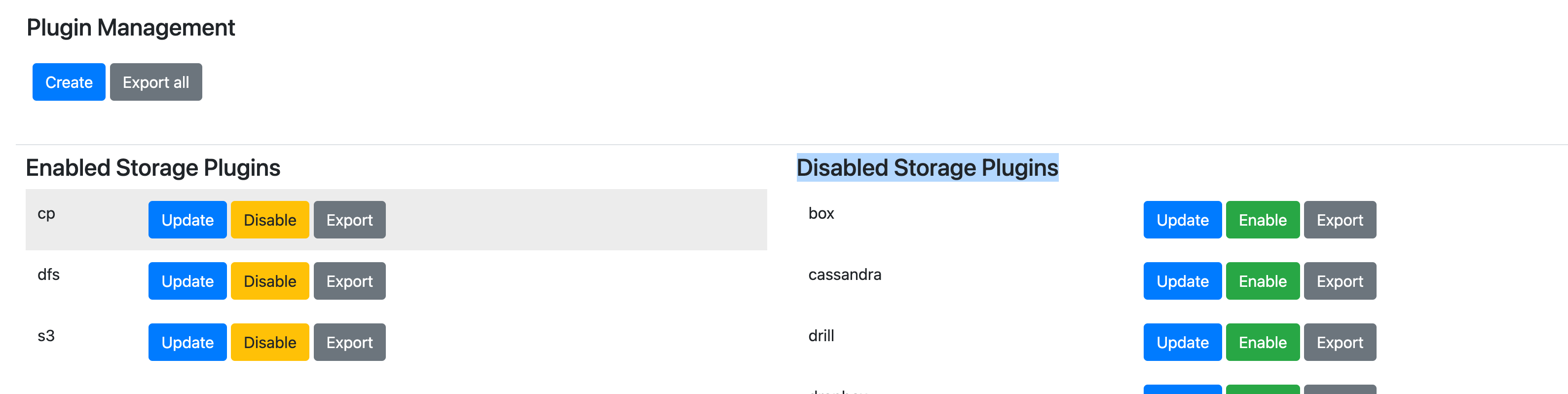
- Click on the update button beside s3 to update the configuration
Here is my configuration file for reference, you need to replace the bucket name and path to match yours
{
"type": "file",
"connection": "s3a://my-s3-bucket-name-where-rds-s3-exports-are-present",
"workspaces": {
"root": {
"location": "/",
"writable": false,
"defaultInputFormat": null,
"allowAccessOutsideWorkspace": false
},
"rds": {
"location": "/databases/mysql/2023/12/15/export-my-db-name-manual-2023-12-15-00-10/db_name/db_name.table_name/1/",
"writable": true,
"defaultInputFormat": null,
"allowAccessOutsideWorkspace": false
}
},
"formats": {
"parquet": {
"type": "parquet"
},
"avro": {
"type": "avro",
"extensions": [
"avro"
]
},
"json": {
"type": "json",
"extensions": [
"json"
]
},
"csvh": {
"type": "text",
"extensions": [
"csvh"
],
"lineDelimiter": "\n",
"fieldDelimiter": ",",
"quote": "\"",
"escape": "\"",
"comment": "#",
"extractHeader": true
},
"sequencefile": {
"type": "sequencefile",
"extensions": [
"seq"
]
},
"psv": {
"type": "text",
"extensions": [
"tbl"
],
"lineDelimiter": "\n",
"fieldDelimiter": "|",
"quote": "\"",
"escape": "\"",
"comment": "#"
},
"tsv": {
"type": "text",
"extensions": [
"tsv"
],
"lineDelimiter": "\n",
"fieldDelimiter": "\t",
"quote": "\"",
"escape": "\"",
"comment": "#"
},
"csv": {
"type": "text",
"extensions": [
"csv"
],
"lineDelimiter": "\n",
"fieldDelimiter": ",",
"quote": "\"",
"escape": "\"",
"comment": "#"
},
"excel": {
"type": "excel",
"extensions": [
"xlsx"
],
"lastRow": 1048576,
"ignoreErrors": true,
"maxArraySize": -1,
"thresholdBytesForTempFiles": -1
},
"msaccess": {
"type": "msaccess",
"extensions": [
"mdb",
"accdb"
]
},
"hdf5": {
"type": "hdf5",
"extensions": [
"h5"
],
"defaultPath": null
},
"delta": {
"type": "delta",
"version": null,
"timestamp": null
},
"spss": {
"type": "spss",
"extensions": [
"sav"
]
},
"xml": {
"type": "xml",
"extensions": [
"xml"
],
"dataLevel": 1
},
"pcap": {
"type": "pcap",
"extensions": [
"pcap",
"pcapng"
]
},
"shp": {
"type": "shp",
"extensions": [
"shp"
]
},
"image": {
"type": "image",
"extensions": [
"jpg",
"jpeg",
"jpe",
"tif",
"tiff",
"dng",
"psd",
"png",
"bmp",
"gif",
"ico",
"pcx",
"wav",
"wave",
"avi",
"webp",
"mov",
"mp4",
"m4a",
"m4p",
"m4b",
"m4r",
"m4v",
"3gp",
"3g2",
"eps",
"epsf",
"epsi",
"ai",
"arw",
"crw",
"cr2",
"nef",
"orf",
"raf",
"rw2",
"rwl",
"srw",
"x3f"
],
"fileSystemMetadata": true,
"descriptive": true
},
"syslog": {
"type": "syslog",
"extensions": [
"syslog"
],
"maxErrors": 10
},
"ltsv": {
"type": "ltsv",
"extensions": [
"ltsv"
],
"parseMode": "lenient",
"escapeCharacter": null,
"kvDelimiter": null,
"entryDelimiter": null,
"lineEnding": null,
"quoteChar": null
},
"pdf": {
"type": "pdf",
"extensions": [
"pdf"
],
"extractHeaders": true,
"extractionAlgorithm": "basic"
},
"sas": {
"type": "sas",
"extensions": [
"sas7bdat"
]
},
"iceberg": {
"type": "iceberg",
"properties": null,
"caseSensitive": null,
"includeColumnStats": null,
"ignoreResiduals": null,
"snapshotId": null,
"snapshotAsOfTime": null,
"fromSnapshotId": null,
"toSnapshotId": null
},
"httpd": {
"type": "httpd",
"extensions": [
"httpd"
],
"logFormat": "common\ncombined"
}
},
"authMode": "SHARED_USER",
"enabled": true
}
Highlighted lines on the preceding configuration file need to be updated before you can use this
- connection - S3 bucket URL ( it use s3a:// protocol which supports 5TB data transfer unlike s3:// or s3n://)
- location - Under workspaces - we have created a new workspace named
rdsunderneath we define the exact path where the parquet files are present, you can create multiple workspaces and point them to individual tables too. Let's say your DB has different tables like mytable1 to 5 you can create multiple workspaces like this- mytable1 ( workspace name) - /databases/mysql/2023/12/15/export-my-db-name-manual-2023-12-15-00-10/db_name/db_name.mytable1/1/
- mytable2 ( workspace name) - /databases/mysql/2023/12/15/export-my-db-name-manual-2023-12-15-00-10/db_name/db_name.mytable2/1/
- mytable3 ( workspace name) - /databases/mysql/2023/12/15/export-my-db-name-manual-2023-12-15-00-10/db_name/db_name.mytable31/
Just to keep things simple I have created a single workspace named rdsand pointing to one of my table parquet files
Directly accessing parquet files from S3
Once it's done you can use the Drill CLI or go to the Drill Web Console Query tab and run the following query
select count(*) from s3.`rds`.`*.parquet`
the table I have connected has 300 parquet files in S3 and about 43 million records stored.
Once the query execution is done. I got a response like this on the web console
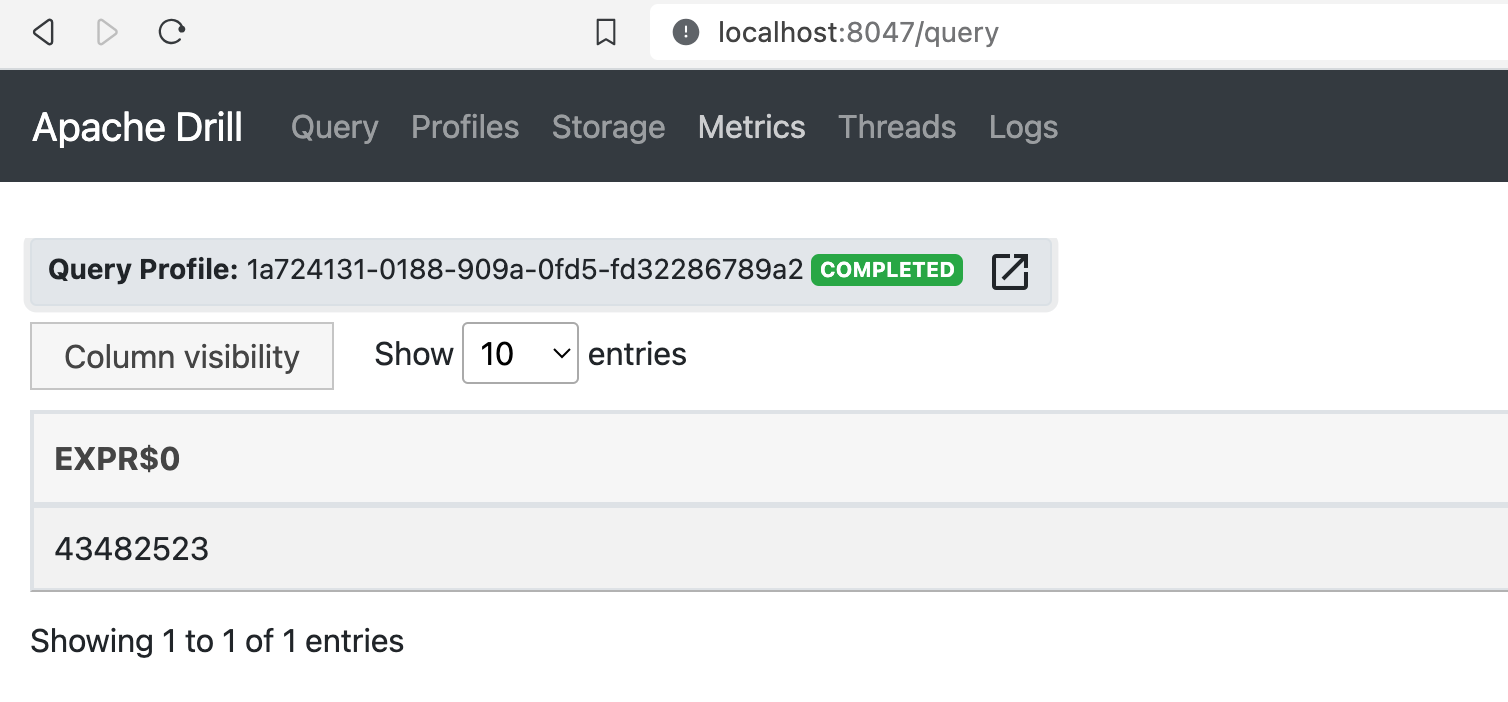
To know more about how much time the query has taken and the finer details of this query. you can click on the Query Profile link shown and it will take you to the query profiling report
Here is what I see as I click on the query profile for this query
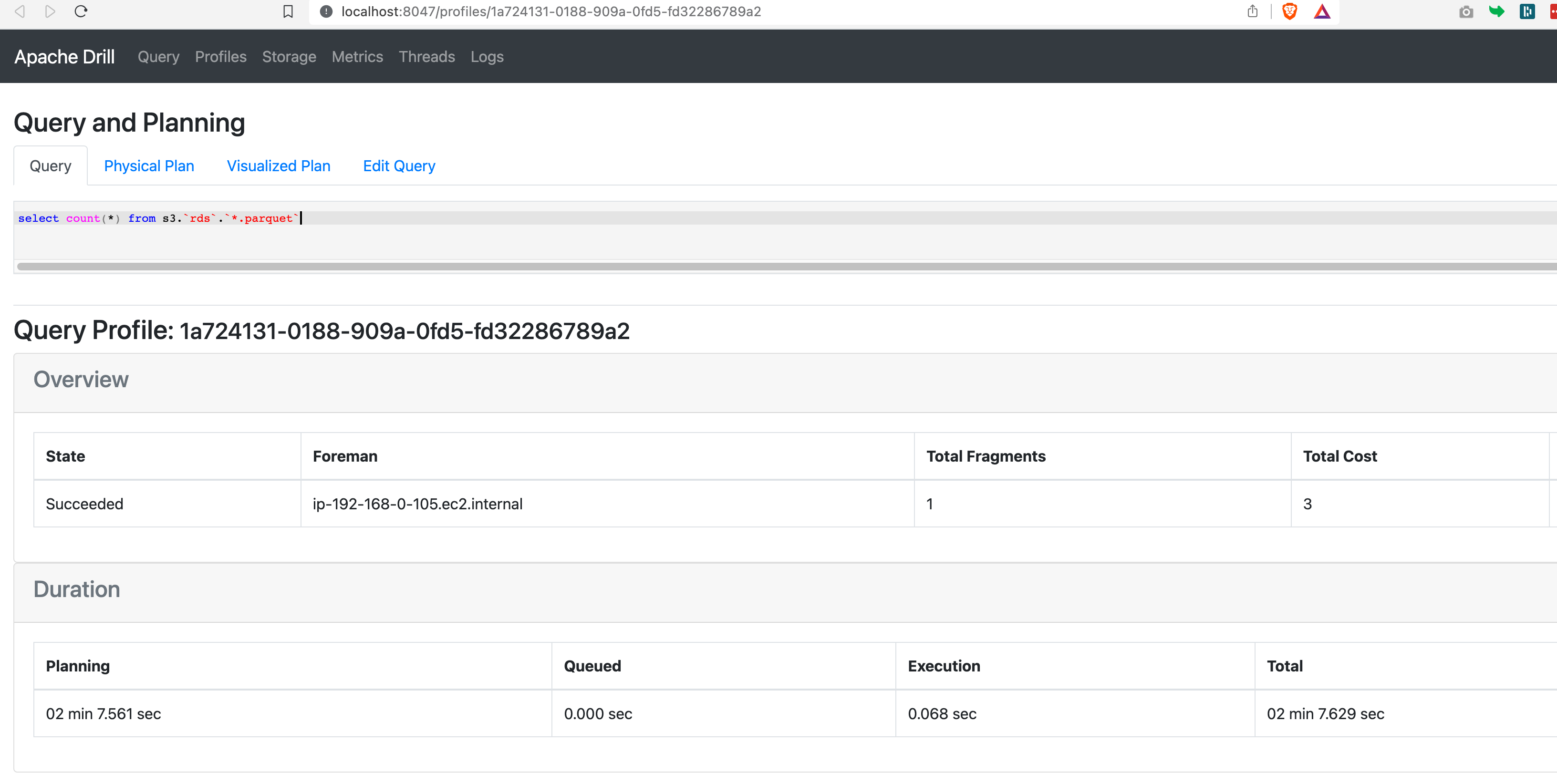
It took the same time through the Drill CLI too

It took 120+ seconds approximately.
Remember I have mentioned earlier about the parquet files being available on the local filesystem and accessed through dfs plugin for efficiency and speed
will benchmark that too now.
Accessing Parquet files from the local filesystem using dfs
I am downloading all the parquet files available in the same S3 directory using aws s3 cp
aws s3 cp s3://my-bucket-name/databases/mysql/2023/12/15/export-my-db-name-manual-2023-12-15-00-10/db_name/db_name.table_name/1/" – recursive
You can see that I have downloaded the 299 parquet files to my local file system - I named the directory as rds where all 299 parquet files are present

Would you believe If I say there is a 99% of performance increment between S3 and DFS(local filesystem)
I ran the same count SQL query through DFS and compared the result
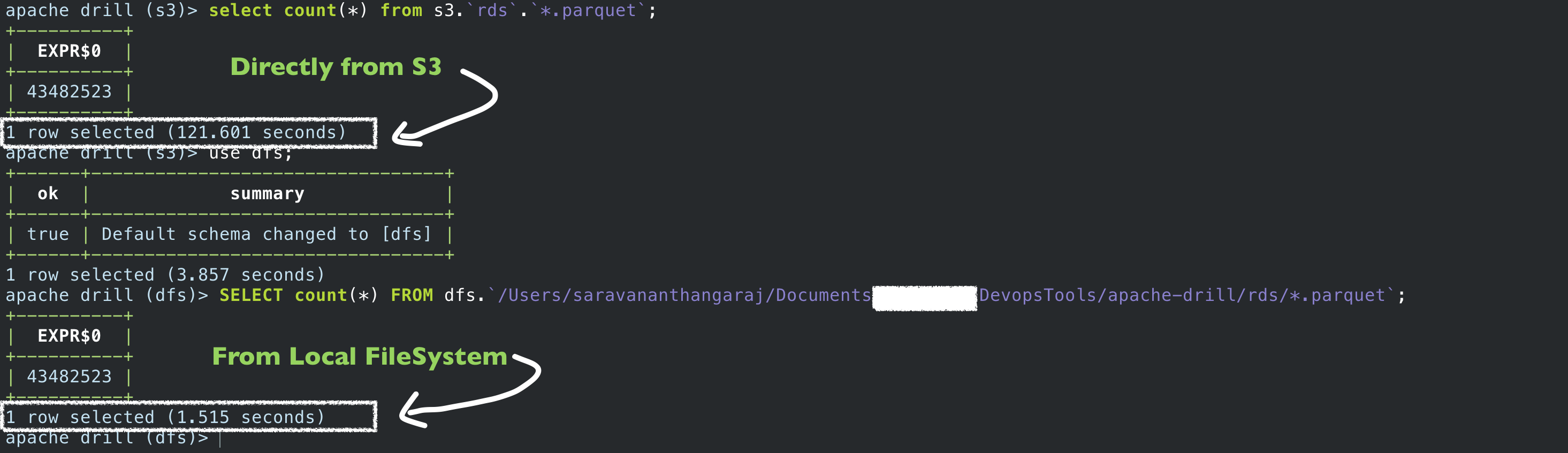
You can see through S3 it took 121 seconds and from the local filesystem, it took 1 second - 99.17% of time decreased
Drill CLI and Web Console are not the only ways to run SQL queries against Apache Drill.
DBeaver Supports Apache Drill - you can use DBeaver Client to issue SQL queries to Apache Drill
I wanted to make the query a little more complex and I made this
SELECT count(*), EXTRACT(year FROM created_time) AS year_of_transaction FROM dfs.`/Users/saravananthangaraj/Documents/MyDir/DevopsTools/apache-drill/rds/*.parquet` GROUP BY year_of_transaction ORDER BY year_of_transaction desc
The query is to get the Count of records per each year. The query uses the created_time field to extract the Year of the transaction
I got my results in 2 seconds. Even with a high-power DB instance (m5.4xlarge) in RDS it took around 2 minutes or more for this query to run.
So this opens up new use cases for the RDS backup parquet files stored in S3. Any Data Analytics and reports and complex time taking SQL can be directed to the parquet files rather than the actual DB
This would save a lot of RDS runtime costs for us as well as reduce the time we wait for our SQL queries to complete - who would not want a 90% performance increment in SQL queries?
Conclusion
Hope you have learnt an interesting use case of Apache RDS S3 backup parquet files and Data Analytics with Apache Drill.
While we have touched only the surface there are a lot to dig in and experiment with these tools. While these tools are primarily used by data engineers - It is not just for them.
Until the Next article.
Cheers
Sarav

Follow me on Linkedin My Profile Follow DevopsJunction onFacebook orTwitter For more practical videos and tutorials. Subscribe to our channel
Signup for Exclusive "Subscriber-only" Content